The Importance of Training Data in AI
Training data is the foundation of artificial intelligence (AI) systems. It is the information that is used to teach AI models how to perform specific tasks and make accurate predictions. Without high-quality training data, AI algorithms would not be able to learn effectively and produce reliable results.
There are several reasons why training data is important in AI:
- Accuracy: The accuracy of an AI model depends on the quality and diversity of the training data. If the training data is incomplete or biased, the AI system may produce inaccurate or biased results.
- Generalization: Training data helps AI models to generalize their knowledge and make predictions on unseen data. By exposing the model to a wide range of examples, it can learn to identify patterns and make accurate predictions in real-world scenarios.
- Adaptability: AI models need to be adaptable and able to handle new and changing data. By continuously training the model with new data, it can adapt and improve its performance over time.
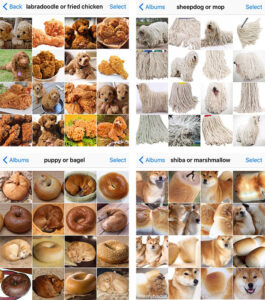
How Supervised Machine Learning Makes Use of Training Data
Supervised machine learning is a popular approach in AI that relies heavily on training data. In supervised learning, the AI model is trained using labeled examples, where each example is paired with the correct output or label.
The process of supervised machine learning involves the following steps:
- Data Collection: A large dataset is collected, consisting of input features and corresponding output labels.
- Data Preprocessing: The collected data is cleaned, normalized, and transformed into a suitable format for training.
- Training: The AI model is trained using the labeled examples from the dataset. The model learns to map the input features to the correct output labels.
- Evaluation: The trained model is evaluated on a separate set of data to measure its performance and accuracy.
- Prediction: Once the model is trained and evaluated, it can be used to make predictions on new, unseen data.
During the training process, the AI model learns from the labeled examples and adjusts its internal parameters to minimize the difference between the predicted output and the actual output. The more diverse and representative the training data is, the better the model can generalize and make accurate predictions on unseen data.
Supervised machine learning algorithms, such as linear regression, decision trees, and neural networks, rely on training data to learn patterns and make predictions. The availability of high-quality training data is crucial for the success of supervised machine learning algorithms.